Największy problem w projektowaniu oprogramowania
Dowiedz się jak rozpoznawać i adresować popularne pułapki w projektowaniu oprogramowania. Zobacz, jak dobre projektowanie może prowadzić do prostszego i niezawodnego kodu.
Zaktualizowano: 10 maja 2025
Najbardziej fundamentalnym problemem w informatyce jest problem dekompozycji: jak wziąć złożony problem i podzielić go na części, które mogą być rozwiązane niezależnie.
Jest to jedno z wprowadzających zdań w książce Johna Ousterhouta „A Philosophy of Software Design”. Autor argumentuje, że w projektowaniu oprogramowania chodzi głównie o złożoność. Jako programiści ciągle walczymy ze złożonością. Powinniśmy ją przestudiować, rozpoznać jej przyczyny i nauczyć się, w jaki sposób ją minimalizować. Nie powinniśmy skupiać się tylko na nauce języków programowania, frameworków czy składni, ale także nauczyć się jak projektować dobre oprogramowanie.
Definicja złożoności
Złożoność to wszystko, co wiąże się ze strukturą oprogramowania i utrudnia zrozumienie oraz modyfikacje systemu.
Definicja jest klarowna. System oprogramowania jest złożony, gdy jest trudny do zrozumienia i modyfikacji. Jestem pewien, że pracowałeś kiedyś nad jakimś przestarzałym kodem spaghetti, więc pewnie wiesz, o czym mówię. Jeżeli system jest łatwy do zrozumienia i modyfikacji, nie jest złożony.
Ogólnie, możemy zdefiniować złożoność systemu, używając następującego równania (jest to jedyne równanie w całym wpisie, obiecuję).
- C - złożoność systemu
- cp - złożoność każdej części
- tp - ilość czasu, jaką programiści spędzają, pracując nad daną częścią
Całkowita złożoność systemu jest sumą złożoności poszczególnych części. Konkretna część jest bardziej złożona, jeżeli programiści poświęcają więcej czasu na pracę z nią.
Złożoność jest bardziej widoczna dla czytelnika niż dla autora kodu—podobnie jak standardowe pisanie. Jeżeli kod wydaje się prosty dla ciebie, ale taki nie jest dla czytelnika, wtedy najprawdopodobniej jest złożony.
Walka ze złożonością
Autor rozpoznaje dwa główne podejścia do walki ze złożonością:
- Spraw, aby kod był prostszy i bardziej oczywisty.
- Enkapsuluj tak, żeby programiści mogli pracować nad systemem bez wystawiania ich na całą złożoność.
Na początek zobaczmy, jak rozpoznawać złożoność, zanim jej dotkniemy.
Najlepszym sposobem na poprawę swoich umiejętności projektowania jest rozpoznawanie czerwonych flag.
Czerwone flagi są często metaforą rozpoznawania toksycznych zachowań w ludziach. Twój najbliższy przyjaciel nie jest szczery? To prawdopodobnie czerwona flaga. Podobnie będziemy próbowali zauważać czerwone flagi w kodzie. Będę o nich wspominał tu i tam w kolejnych paragrafach. Gdy rozpoznasz czerwoną flagę w kodzie, jest to znak, że fragment kodu jest bardziej złożony, niż być powinien—czas na refaktoryzację czy przepisywanie. W książce „Refaktoryzacja. Ulepszanie struktury istniejącego kodu” Martin Fowler używa terminu „zapachy kodu”. Idea jest podobna, ale ja będę się trzymał czerwonych flag i wykorzystam odpowiednie emoji 🚩
Symptomy złożoności
Autor podkreśla trzy, główne symptomy złożoności.
Amplifikacja zmian
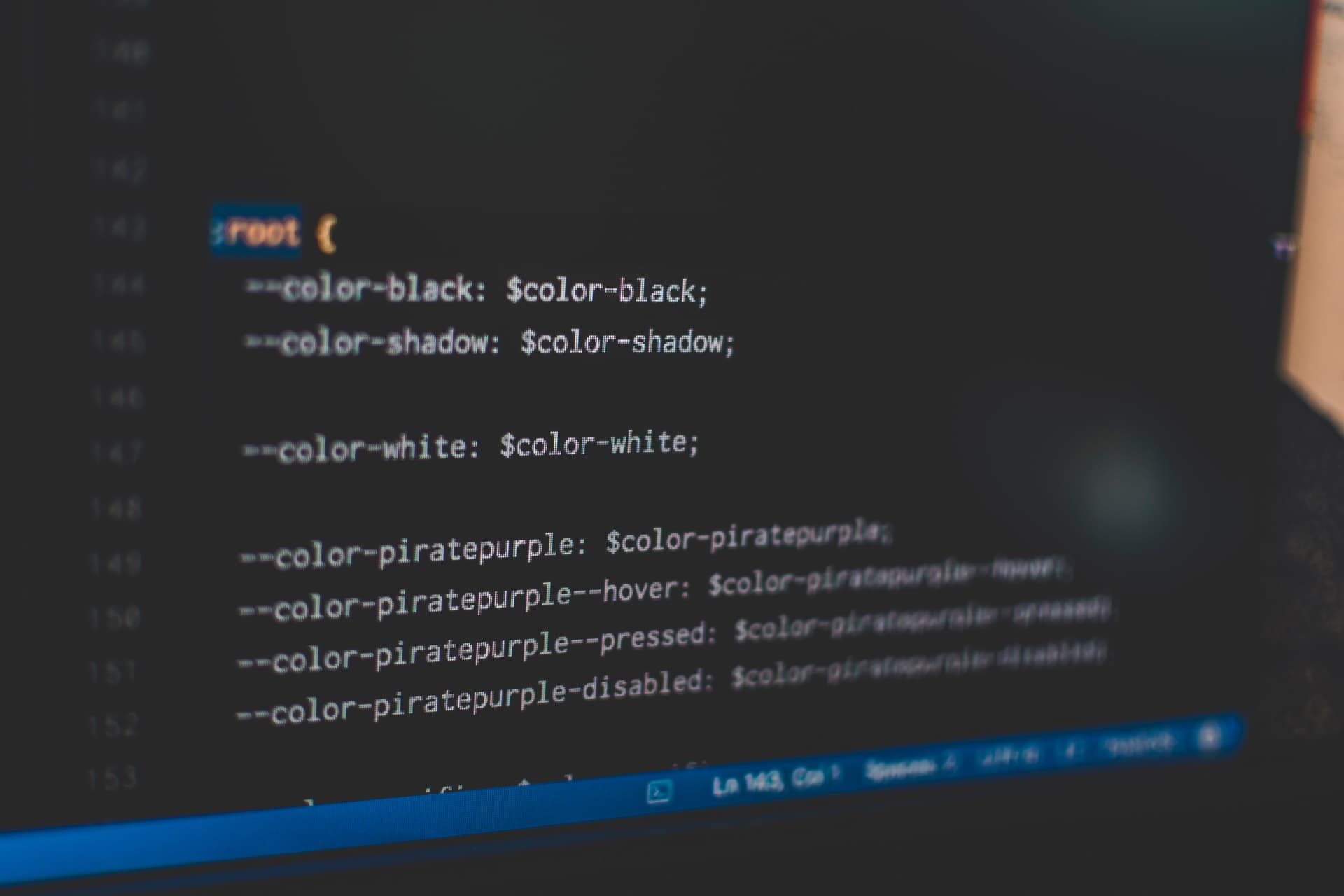
Pierwszym z nich jest amplifikacja zmian. Mamy do czynienia z amplifikacją zmian, gdy pozornie prosta zmiana wymaga modyfikacji kodu w wielu miejscach.
Wyobraź sobie scenariusz, w którym masz witrynę internetową z wieloma stronami. Najprawdopodobniej byłyby tam jakieś kolory i spójność. Zamiast używać kolorów ad hoc, w stylu color: hsl(210, 96%, 40%), możesz zdefiniować zmienną CSS i przypisać jej wartość --color-primary-500: hsl(210, 96%, 40%). Następnym razem, gdy jakiś „stabilny geniusz” wymusi znaczący rebranding na stronie, zmieniając całą paletę kolorów, nie będzie to problem — zmiany będzie wymagała tylko wartość zmiennej, zamiast zmiany kolorów w wielu miejscach.
Celem dobrego designu jest redukcja ilości kodu dotkniętego przez każdą z projektowych decyzji, w taki sposób, że zmiany projektowe nie wymagają zmian kodu w wielu miejscach.
Obciążenie poznawcze
Drugim symptomem złożoności jest obciążenie poznawcze. Odnosi się ono do informacji i ograniczeń ludzkiego mózgu — jak wiele informacji programista musi wiedzieć, aby wykonać zadanie.
Obciążenie poznawcze może pojawić się na wiele sposobów:
- API z wieloma metodami
- globalne zmienne
- niespójności
- zależności pomiędzy modułami
- jakiś „magiczny kod” pod maską
Większe obciążenie poznawcze oznacza, że programista musi spędzić więcej czasu na nauce niezbędnych informacji, zamiast dostarczać wartość. Dodatkowo istnieje większe ryzyko pojawienia się błędów, bo mogą pominąć coś istotnego.
Oczywiście obciążenie poznawcze nie jest ściśle powiązane z liczbą linii kodu. Czasami podejście, które wymaga więcej linii kodu, jest bardziej przejrzyste, ponieważ redukuje obciążenie. Zobacz na ten operator trójskładnikowy zastąpiony przez instrukcje if.
// prettier-ignore
pet.canBark() ? pet.isScary() ? 'wolf' : 'dog' : pet.canMeow() ? 'cat' : 'probably a bunny'if (pet.canBark() && pet.isScary()) {
return 'wolf'
}
if (pet.canBark()) return 'dog'
if (pet.canMeow()) return 'cat'
else return 'probably a bunny'Nieznane nieznane
Ostatnia z trzech manifestacji złożoności jest najgorsza. „Nieznane nieznane” oznaczają, że nie jest oczywiste, które fragmenty kodu muszą zostać zmodyfikowane, aby zakończyć zadanie, lub które informacje musi posiadać programista, aby zakończyć zadanie.
Ta manifestacja nawiązuje do macierzy świadomość-zrozumienie. Macierz ta pochodzi z konferencji prasowej z 2002 roku o wojnie w Iraku. Donald Rumsfeld — sekretarz obrony Stanów Zjednoczonych — podzielił informacje na cztery kategorie.
| Świadomy | Nieświadomy | |
|---|---|---|
| Rozumie | Znane znane | Nieznane znane |
| Nie rozumie | Znane nieznane | Nieznane nieznane |
- Znane znane - fakty lub zmienne, o których istnieniu jesteśmy świadomi i je rozumiemy.
- Nieznane znane - czynniki, o których wiemy, że istnieją, ale w pełni ich nie rozumiemy.
- Znane nieznane - elementy, z których sobie nie zdajemy sprawy, że je wiemy.
- Nieznane nieznane - czynniki, których nie jesteśmy świadomi i których nie możemy przewidzieć.
Łatwo sobie wyobrazić, że nieświadomość niektórych mechanizmów systemu może prowadzić do paskudnych bugów. Dlatego jednym z ważniejszych celów dobrego designu jest, aby system był oczywisty. To jest przeciwieństwo obciążenia poznawczego i nieznanych nieznanych.
Przyczyny złożoności
Znając symptomy, możemy przejść do przyczyn złożoności. Autor podkreśla dwie główne przyczyny.
Zależności
Pierwszą przyczyną złożoności są zależności. Zależność istnieje, gdy jeden fragment kodu zależy od innego. Dany fragment nie może być zrozumiany i modyfikowany w izolacji.

One mogą być szczególnie problematyczne w ekosystemie JavaScript, gdzie mamy zewnętrzną paczkę na wszystko. Bogaty ekosystem paczek jest dobry, ale zanim zainstalujesz cokolwiek, zadaj sobie pytanie: „Czy aby na pewno potrzebuję tej paczki?”. Nie popieram wymyślania koła na nowo, ale często możesz napisać funkcję czy skrypt bez ładowania rozdętych bibliotek.

Celem dobrego designu jest decydowanie o liczbie zależności i uczynienie ich tak prostymi i oczywistymi jak to możliwe.
Niejasności
Drugą przyczyną złożoności są niejasności. Pojawiają się, gdy kluczowa informacja nie jest oczywista. W wielkim projekcie z wieloma zależnościami łatwo stracić nad nimi rachubę. Niejasności pojawiają się, gdy nie jest oczywiste czy zależność istnieje.

Niespójności grają także kluczową rolę w niejasności. Nietrzymanie się konwencji, używanie nazw zmiennych dla dwóch innych celów lub posiadanie podobnych funkcji, w których parametry mają pomieszane pozycje, może prowadzić do niejasności.
W poprzednich paragrafach można było zaobserwować pewne analogie. Łącząc symptomy z przyczynami, otrzymujemy następujące konkluzje.
- Zależności prowadzą do amplifikacji zmian i wysokiego obciążenia poznawczego.
- Niejasności tworzą nieznane nieznane, a także przyczyniają się do obciążenia poznawczego.
Złożoność pojawia się, ponieważ setki tysięcy małych zależności i niejasności nakładają się na siebie z czasem. Trudno jest się pozbyć złożoności po tym, jak już się zakumulowała. Naprawienie pojedynczej zależności lub niejasności nie zrobi większej różnicy.
Działający kod nie wystarczy
W tym momencie mamy dobre zrozumienie złożoności. Znamy jej symptomy oraz przyczyny. Jednak żeby poradzić sobie z tym problemem, potrzebujemy także dobrego sposobu myślenia. Autor prezentuje dwa podejścia do programowania. Dla mnie brzmią jak synonimy, ale nie będę zmieniał terminologii i postaram się je rozróżnić odpowiednio.
- Taktyczne programowanie jest pierwszym podejściem. Twoim głównym celem jest sprawienie, aby coś działało — dodanie funkcjonalności lub naprawienie buga.
- Strategiczne programowanie jest drugim podejściem. Musisz zainwestować czas, w celu poprawy projektu systemu, zamiast podążać najkrótszą ścieżką, aby ukończyć bieżący projekt.
Drugie podejście jest preferowanym sposobem programowania. Jednakże wymaga inwestycyjnego podejścia. Potrzebujesz czasu, żeby doszlifować i oczyścić swoje rozwiązanie. Oczywiście czasami terminy ostateczne są… ostateczne. Nie ma czasu na refaktoryzację lub nawet na pisanie testów. Jednak musisz uważać, wykorzystując pierwsze podejście. Taktyczne programowanie jest krótkowzroczne. Pożyczasz czas od siebie z przyszłości i tworzysz dług techniczny. Złożoności akumulują się szybko, szczególnie gdy wszyscy programują taktycznie. Naczelną zasadą powinno być ulepszanie długoterminowego projektu systemu. Dlatego powinieneś spędzać 10-20% swojego czasu programowania na inwestycjach. Jest to sugestia — arbitralna liczba. Jednakże jest to dobra liczba na początek.
Spędź 10-20% całkowitego czasu rozwijania oprogramowania na inwestycjach.
Modułowy design
Jesteśmy świadomi problemu, ale jak go zaadresować? Jedną z najskuteczniejszych strategii zarządzania złożonym systemem jest podział na mniejsze komponenty i wprowadzanie programistów do każdego z nich pojedynczo. Takie podejście jest znane jako modułowy design.
W modułowym projektowaniu system oprogramowania jest zdekomponowany na kolekcję modułów, które są relatywnie niezależne. Moduły to nie tylko klasy! Są one bardziej abstrakcyjne i mogą przyjąć różne formy, takie jak:
- klasy
- podsystemy
- serwisy
- funkcje
Celem modułowego projektowania jest minimalizowanie zależności pomiędzy modułami. Oczywiście te zależności muszą współdziałać, dlatego nie możesz ich całkowicie oddzielić, ale chcesz zminimalizować te zależności.
Jak wygląda anatomia modułu? Moduł składa się z dwóch części: interfejsu i implementacji. Interfejs zawiera wszystko, co programista musi wiedzieć, aby użyć danego modułu. Implementacja zawiera kod, który spełnia obietnicę złożoną przez interfejs.

Interfejs opisuje, co moduł robi, ale nie jak to zrobić. Implementacja odpowiada na drugie pytanie.
Abstrakcja to uproszczony obraz jednostki, opuszczająca nieistotne detale. Abstrakcje są przydatne, ponieważ upraszczają nasze myślenie i manipulacje złożonymi rzeczami.
Termin abstrakcji jest blisko związany z modułowym projektowaniem. Możemy połączyć definicję abstrakcji z modułami — każdy moduł dostarcza abstrakcji w formie swojego interfejsu.
Głębokie moduły kontra płytkie moduły
Teraz przechodzimy do ciekawych rzeczy. Mam nadzieję, że poprzednie sekcje były także ciekawe, ale ta powinna być w szczególności (a jeżeli były nudne, może rozbudzę twoją ciekawość). Autor stwierdza, że najlepsze moduły powinny być głębokie — powinny mieć dużo funkcjonalności za prostym interfejsem.

Podoba mi się ta prosta, graficzna interpretacja, którą przerysowałem z książki. Podłużny prostokąt reprezentuje głębokie moduły — interfejs jest wąski, ale przykrywa wiele funkcjonalności pod spodem. Z drugiej strony mamy płytkie moduły. Ich interfejs jest szeroki z niewielką funkcjonalnością. Płytkie moduły to nasza pierwsza czerwona flaga.
Płytki moduł to taki, którego interfejs jest skomplikowany relatywnie do funkcjonalności, którą dostarcza. Płytkie moduły nie pomagają za bardzo w walce przeciwko złożoności, ponieważ ich korzyści są negowane przez koszt nauki i używania ich interfejsów.
Jeżeli wolisz ekonomiczną analogię, możemy rozpatrywać moduły na zasadzie kosztów i korzyści. Korzyść modułu leży w jego funkcjonalności, natomiast kosztem jest jego interfejs.
Classistis
Istnieje choroba, która zatruwa systemy wieloma płytkimi modułami i nazywa się „classistis”. W takich systemach programiści są zachęcani do minimalizowania ilości funkcjonalności w każdej z nowych klas. Pewnie, klasy same w sobie są jasne, ale system jako całość już nie jest. Naszym celem powinna być minimalizacja ogólnej złożoności systemu.
Java ma podobny problem. Potrzebujesz skomplikowanego szablonu kodu z wieloma importami, żeby otworzyć zwykły plik.
import static java.nio.file.StandardOpenOption.*;
import java.nio.file.*;
import java.io.*;
public class LogFileTest {
public static void main(String[] args) {
// Convert the string to a
// byte array.
String s = "Hello World! ";
byte data[] = s.getBytes();
Path p = Paths.get("./logfile.txt");
try (OutputStream out = new BufferedOutputStream(
Files.newOutputStream(p, CREATE, APPEND))) {
out.write(data, 0, data.length);
} catch (IOException x) {
System.err.println(x);
}
}
}JavaScript ma swoje problemy, ale jestem wdzięczny, że Brendan Eich stworzył go podobnym do Javy, ale „nie za bardzo”.
Jak pogłębić moduły?
Wiemy, że płytkie moduły są problematyczne, więc jak je pogłębić? Problem sprowadza się do zestawienia ogólności i specjalizacji. Nadmierna specjalizacja może być najbardziej jasną przyczyną złożoności oprogramowania. Podobnie możesz skomplikować swoje życie. Bycie specjalistą jest dobre (szczególnie dla twojego portfela), ale możesz mieć problemy komunikacyjne z innymi. Jeżeli chcesz skutecznie współpracować z pisarzami, projektantami czy testerami, powinieneś znać przynajmniej podstawy w tych dziedzinach. Istnieje znana metafora umiejętności w kształcie litery „T”, która zgrabnie to ilustruje, ale zagłębiam się w dygresje. Wróćmy do modułów.
Ukrywanie i wyciek informacji
Autor wspomina ukrywanie informacji jako jedną z najważniejszych technik osiągania głębokich modułów. Ukrywanie informacji oznacza, że powinniśmy redukować ilość informacji potrzebnych do pracy z danym modułem. Wiedza zawarta w implementacji modułu nie powinna pojawiać się w jego interfejsie i być wystawiona innym modułom. Możemy tu wykorzystać analogię czarnej skrzynki—ukrywanie informacji to traktowanie każdego modułu jak nieprzezroczystej, czarnej skrzynki. Nie musisz wiedzieć, co się dzieje wewnątrz, aby go wykorzystać. Ukrywanie informacji redukuje złożoność na dwa sposoby:
- Upraszcza interfejs modułu.
- Ułatwia ewolucję systemu.
Słabo zaprojektowane, niemodułowe komponenty często wymagają przypadkowych, dodatkowych informacji, ujawniając wewnętrzne działanie. Te dodatkowe informacje to forma wycieku. Wyjawiasz detale implementacyjne do użytkownika modułu.
Wyciek informacji pojawia się, gdy ta sama wiedza jest użyta w wielu miejscach, jak w dwóch różnych klasach, które rozumieją format konkretnego typu pliku.
Wyciek informacji to krytyczna czerwona flaga w projektowaniu oprogramowania. Rozwijanie wrażliwości na wyciek informacji jest jedną z najbardziej wartościowych umiejętności, jakie projektant oprogramowania może posiąść.
Wartości domyślne
Wartości domyślne ilustrują zasadę, że interfejsy powinny być zaprojektowane w sposób, aby najczęstszy przypadek był tak prosty, jak to możliwe.
Jeżeli API dla najczęstszego przypadku zmusza użytkowników, aby uczyli się o rzadkich funkcjonalnościach, zwiększa to obciążenie poznawcze użytkowników, którzy nie potrzebują tych funkcjonalności.
Pokażę przykład z mojego repozytorium. W kodzie mam funkcje pomocnicze do procesowania plików MDX (format moich wpisów na blogu).
export async function getMDXes<Type extends MDXTypes>(
page: Extract<Pages, (typeof LINKS)['blog' | 'portfolio']>,
lang: Locale,
number: number | 'all' = 'all',
sort: 'asc' | 'desc' | 'none' = 'none'
) {
// Ciało funkcji
}Funkcja getMDXes() zwraca pliki MDX dla konkretnej strony. Mogę uzyskać wiele takich plików posortowanych po dacie. Jak widzisz, wykorzystuje dwie wartości domyślne. Przez większość czasu, chcę wszystkie, nieposortowane pliki, więc ma to sens.
Moduły ogólnego przeznaczenia
Jeżeli nadmierna specjalizacja powoduje złożoność, powinniśmy jej unikać. Powinno mieć to intuicyjny sens — kilka, uniwersalnych metod jest prostszych w użyciu. Redukuje to obciążenie poznawcze. Jednakże, jak z wieloma rzeczami, warto dążyć do balansu. Implementowanie czegoś, co jest za bardzo ogólne, może słabo rozwiązywać problem, który masz dziś. Dlatego celem powinno być implementowanie nowych modułów, które są ✨nieco✨ ogólnego przeznaczenia. Można to rozumieć tak, że funkcjonalność modułu powinna odzwierciedlać twoje aktualne potrzeby, ale interfejs nie.
Usuń przypadki szczególne
Przypadki brzegowe mogą się ukrywać w ciałach funkcji, zwiększając specjalizację kodu. Takie kod jest wypełniony instrukcjami warunkowymi, utrudniającymi jego zrozumienie i czyniącymi go podatnymi na błędy. „Dobra Mateusz, ale jak mam w takim razie obsługiwać takie przypadki?”. Projektowanie kodu, gdzie standardowy przypadek automatycznie obsługuje przypadki brzegowe, powinno pomóc. Nie zawsze jest to możliwe, ale powinniśmy je eliminować tam, gdzie to możliwe.
Razem czy osobno
„Będą ze sobą czy nie?”. Dobry romans nie może się obejść bez tej techniki opowiadania historii. Może złapać nas emocjonalnie i przykuć do ekranu. Kod też potrafi przykuć do ekranu, ale bez tego emocjonalnego bagażu (no, chyba że jest popołudniowy piątek, a ty próbujesz naprawić produkcję). Jednakże podobnie jak w dobrym romansie, dobry kod powinien wywołać podobne pytanie — powinni być razem czy osobno? Niektóre wskazówki ilustrują, że pewne fragmenty kodu są powiązane.
- Połącz razem, jeżeli dzielą informacje. Oddzielenie sprawia, że trudniej jest programistom widzieć komponenty w tym samym momencie czy nawet być świadomym ich istnienia.
- Połącz razem, jeżeli upraszcza to interfejs. Kiedy klasy lub metody dzielą informacje, zbliż je do siebie, aby poprawić czytelność. Kod stanie się prostszy i krótszy.
- Połącz razem, aby wyeliminować duplikację. Kiedy co najmniej dwa moduły zostają połączone w jeden, jest możliwe, aby zdefiniować interfejs dla nowego modułu, który jest prostszy lub łatwiejszy w użyciu niż ten oryginalny.
Jeżeli ten sam fragment kodu (albo prawie ten sam) pojawia się raz za razem, jest to czerwona flaga, oznaczająca, że brakuje odpowiednich abstrakcji.
- Rozdziel kod ogólnego i specjalnego przeznaczenia. Jeżeli zauważysz jakiś wzorzec w kodzie powtórzony wielokrotnie, sprawdź, czy jesteś w stanie wyeliminować powtórzenie.
Ta czerwona flaga pojawia się, gdy mechanizm ogólnego przeznaczenia zawiera także wyspecjalizowany kod dla konkretnego przypadku tego mechanizmu. Komplikuje to ten mechanizm i tworzy wyciek informacji pomiędzy mechanizmem a konkretnym przypadkiem — przyszłe modyfikacje tego przypadku będą najprawdopodobniej wymagały zmian w podstawowym mechanizmie.
Dzielenie i łączenie metod
Pierwsza zasada dotycząca konstruowania funkcji jest taka, że powinny być małe. Druga zasada mówi, że powinny być mniejsze, niż są.
— Robert C. Martin
Prawdopodobnie znasz „wujka Boba” i jego przemyślenia dotyczące funkcji z „Czystego kodu”. Klasyka. No i… zamierzam z nią polemizować. W zasadzie John Ousterhou polemizuje z nią. Myśli on, że długość sama w sobie jest rzadko dobrym powodem, aby podzielić metodę. Podział metody wprowadza dodatkowe interfejsy, które zwiększają złożoność. Dla mnie ma to sens. Jest to ciekawa alternatywa dla perspektywy „wujka”. Krótkie funkcje są ogólnie łatwiejsze do zrozumienia — wiadomo. Jednakże naszym celem powinno być redukowanie ogólnej złożoności systemu. Jeżeli funkcje są zbyt małe, tracą niezależność, są połączone i muszą być czytane i rozumiane razem.
Powinno dać się zrozumieć każdą z metod niezależnie. Jeżeli nie możesz zrozumieć implementacji jednej metody bez zrozumienia implementacji innej, jest to czerwona flaga.
Decyzja, aby podzielić lub złączyć moduły, powinna bazować na złożoności. Wybierz strukturę, która najlepiej ukryje informacje, będzie miała jak najmniej zależności i głębokie interfejsy. Istnieje kilka sposobów na efektywny podział metod.
Wyodrębnienie podzadania
Najlepszym sposobem na podział metody jest wydzielenie z niej podrzędnego zadania do oddzielnej metody. W wyniku takiego podziału mamy metodę „dziecko” z podrzędnego zadania i metodę „rodzica” przypominającą oryginalną metodę. Rodzic wywołuje dziecko. Taki podział nie zmienia interfejsu. Interfejs nowej metody-rodzica jest taki sam jak oryginalnej metody.

Ponownie wykorzystam przykład z mojego repozytorium.
export async function getMDXes<Type extends MDXTypes>(
page: Extract<Pages, (typeof LINKS)['blog' | 'portfolio']>,
lang: Locale,
number: number | 'all' = 'all',
sort: 'asc' | 'desc' | 'none' = 'none'
) {
const slugs = await getMDXSlugs(page)
const mdxes = await Promise.all(
slugs.map((slug) => getCachedMDX<Type>(page, slug, lang))
)
const sorted = sort === 'none' ? mdxes : sortMDXes<Type>(mdxes, sort)
const filtered =
number === 'all' ? sorted : sorted.filter((_, index) => index < number)
return filtered
}Funkcja getMDXes() zwraca pliki MDX dla konkretnej strony. Mogę uzyskać wiele plików posortowanych po dacie. Na początku cała logika — łącznie z sortowaniem — była wewnątrz tej jednej funkcji. Wyodrębniłem to zadanie z funkcji-rodzica do innej. Nowa metoda jest krótsza, łatwiejsza do przeczytania i łatwiej nią zarządzać. Interfejs pozostaje bez zmian.
Dwie oddzielne metody
Drugim sposobem na rozbicie metody, jest podział na dwie oddzielne metody, gdzie każda z nich jest widoczna dla wywołujących oryginalnej metody. Ma to sens, jeżeli oryginalna metoda ma bardzo zawiły interfejs, ponieważ próbowała robić wiele, niepowiązanych ze sobą rzeczy. Jeżeli wykonujesz taki podział, interfejs każdej z metody powinien być prostszy niż interfejs oryginalnej metody.

Wiele metod
Tu trzeba być ostrożnym. Jeżeli dzielisz metodę w ten sposób, ryzykujesz, że skończysz z wieloma płytkimi metodami. Możesz rozważyć taki podział, ale powinieneś uwzględnić czy to upraszcza rzeczy dla wywołujących.

Wybieranie nazw
Docieramy do innego wielkiego problemu w inżynierii oprogramowania — nazywania rzeczy. Wybieranie nazw dla zmiennych, metod i innych jednostek jest jednym z najbardziej niedocenianych aspektów dobrego oprogramowania. Dobre nazwy są formą dokumentacji — sprawiają, że kod jest łatwiejszy do zrozumienia. Nie powinieneś zadowalać się nazwami, które są „wystarczająco blisko”. Poświęć więcej czasu na wybór świetnych nazw, które są precyzyjne, jednoznaczne i intuicyjne. Ja to zrobić? Przekonajmy się.
Stwórz obraz
„Obraz jest wart więcej niż tysiąc słów”. Jest sporo prawdy w tej starej frazie. Niestety nie możemy używać zdjęć lub emoji jak nazw zmiennych (a przynajmniej nie w JS/TS). A szkoda, bo pszczoła jest kojarzona z brzęczeniem i mogłaby symbolizować aktualizacje na moim blogu. Jednakże wybierając nazwy, możemy stworzyć obraz w umyśle czytelnika. Dobra nazwa przekazuje wiele informacji o jednostce pod spodem. „Jeżeli ktoś zobaczy tę nazwę w izolacji, czy będzie w stanie zgadnąć, do czego się odnosi?”. Tego typu pytania mogą pomóc ci w malowaniu jasnego obrazu. Możesz myśleć o nazwach jako o formie abstrakcji — czy dostarczają uproszczonego sposobu myślenia o bardziej złożonej jednostce, leżącej pod spodem.
Nazwy powinny być precyzyjne
Dobra nazwa ma dwie cechy: spójność i precyzję. I z tymi dwoma cechami wiążą się dwie czerwone flagi.
Jeżeli nazwa zmiennej czy metody jest wystarczająco szeroka, aby odnosić się do wielu różnych rzeczy, wówczas nie przekazuje programiście zbyt wielu informacji o jednostce, do której się odnosi i może zostać błędnie użyta.
Jeżeli trudno jest wybrać prostą nazwę dla zmiennej czy metody, która tworzyłaby jasny obraz obiektu leżącego pod spodem, jest to wskazówka, że ten obiekt może nie mieć czystego projektu.
Konsekwentnie używaj nazw
Skoro już wymieniamy rzeczy, spójność ma trzy wymagania:
- Zawsze używaj nazwy zwyczajowej dla danego celu.
- Nigdy nie używaj nazwy zwyczajowej dla celu innego niż dany.
- Upewnij się, że cel jest na tyle wąski, że wszystkie zmienne o danej nazwie mają takie samo zachowanie.
Spójne nazewnictwo redukuje jeden symptom złożoności — obciążenie poznawcze. Kiedy czytelnik widział nazwę w danym kontekście, może wykorzystać tę wiedzę i natychmiast mieć założenia dotyczące innego kontekstu.
Unikaj dodatkowych słów
Każde słowo w nazwie powinno dostarczać przydatnych informacji — słowa, które nie pomagają wyklarować znaczenia zmiennej, tylko wprowadzają nieład. Jednym, popularnym błędem jest dodawanie ogólnych rzeczowników takich jak „array” czy „object” do nazwy. Sam byłem tego winien.

Notacja węgierska jest konwencją dla zmiennych, gdzie jej nazwa sugeruje typ, wykorzystując prefiks nazwany „wskaźnikiem typu”. Wcześni programiści C/C++ wykorzystywali ją, aby identyfikować typy zmiennych. Jednakże konwencja ta jest przestarzała we współczesnych silnie typowanych językach jak TypeScript czy Python. A zatem Polak, Węgier, nie dwa bratanki, najwyraźniej.
Czytelnicy powinni decydować o czytelności, a nie pisarz kodu — podobnie do pisania po polsku. Jeżeli piszesz kod z krótkimi nazwami zmiennych, a ludziom, którzy go czytają, wydaje się prosty do zrozumienia — w porządku.
Pomyśl dwa razy
Wszystko, o czym piszę, może być podsumowane tą jedną sentencją, oznaczającą, że powinieneś myśleć więcej i pisać mniej — w erze AI i kodujących agentów, jest to szczególnie istotne.
Uzyskasz znacznie lepszy rezultat jeżeli rozważysz wiele opcji przed podjęciem każdej, ważnej projektowej decyzji.
— John Ousterhout, "A Philosophy of Software Design"