The biggest problem in software design
Learn how to spot and address common pitfalls in software projects. See how thoughtful design choices can lead to simpler, more robust code.
Last updated: May 10, 2025
The most fundamental problem in computer science is problem decomposition: how to take a complex problem and divide it up into pieces that can be solved independently.
That's one of the introductory sentences in John Ousterhout's book “A Philosophy of Software Design.” The author argues that designing software is all about complexity. As programmers, we constantly battle complexity. We should study it, recognize its causes, and learn how to minimize it. We shouldn't only focus on learning programming languages, frameworks, or syntax but also learn how to design good software.
Defining complexity
Complexity is anything related to the structure of a software system that makes it hard to understand and modify the system.
The definition is straightforward. A software system is complicated when it's hard to understand and modify. I'm sure you've worked on some legacy spaghetti codebase, so you know what I'm talking about. If the system is easy to understand and modify, it is simple.
Overall, we can define the system's complexity using the following equation (the only equation in this post, I promise).
- C—complexity of a system
- cp—complexity of each part
- tp—fraction of time developers spend working on that part
The total complexity of a system is the sum of the complexity of the individual parts. The part is more complex when developers spend more time working on it.
Complexity is more apparent to readers than to code writers—similar to standard writing. If the code seems simple to you but not to the reader, then it probably is complex.
Fighting complexity
The author recognizes two general approaches to fighting complexity:
- Make code simpler and more obvious.
- Encapsulate so programmers can work on a system without being exposed to all its complexity.
First, let's see how to recognize complexity before touching it.
The best way to improve your design skills is to recognize red flags.
Red flags are often a metaphor for recognizing toxic behaviors in people. Your close friend is dishonest? That's probably a red flag. Similarly, we'll be trying to spot red flags in the code. I'll list them here and there in the following paragraphs. When you spot a red flag in your code, that's a sign that a piece of code is more complicated than it needs to be—it's time to do some rewriting or refactoring. In his book “Refactoring: Improving the Design of Existing Code,” Martin Fowler uses the term “code smells.” The idea is similar, but I will stick to red flags and use an appropriate emoji 🚩
Symptoms of complexity
The author highlights three main symptoms of complexity.
Change amplification
The first is change amplification. We deal with change amplification when a seemingly simple change requires code modification in many places.
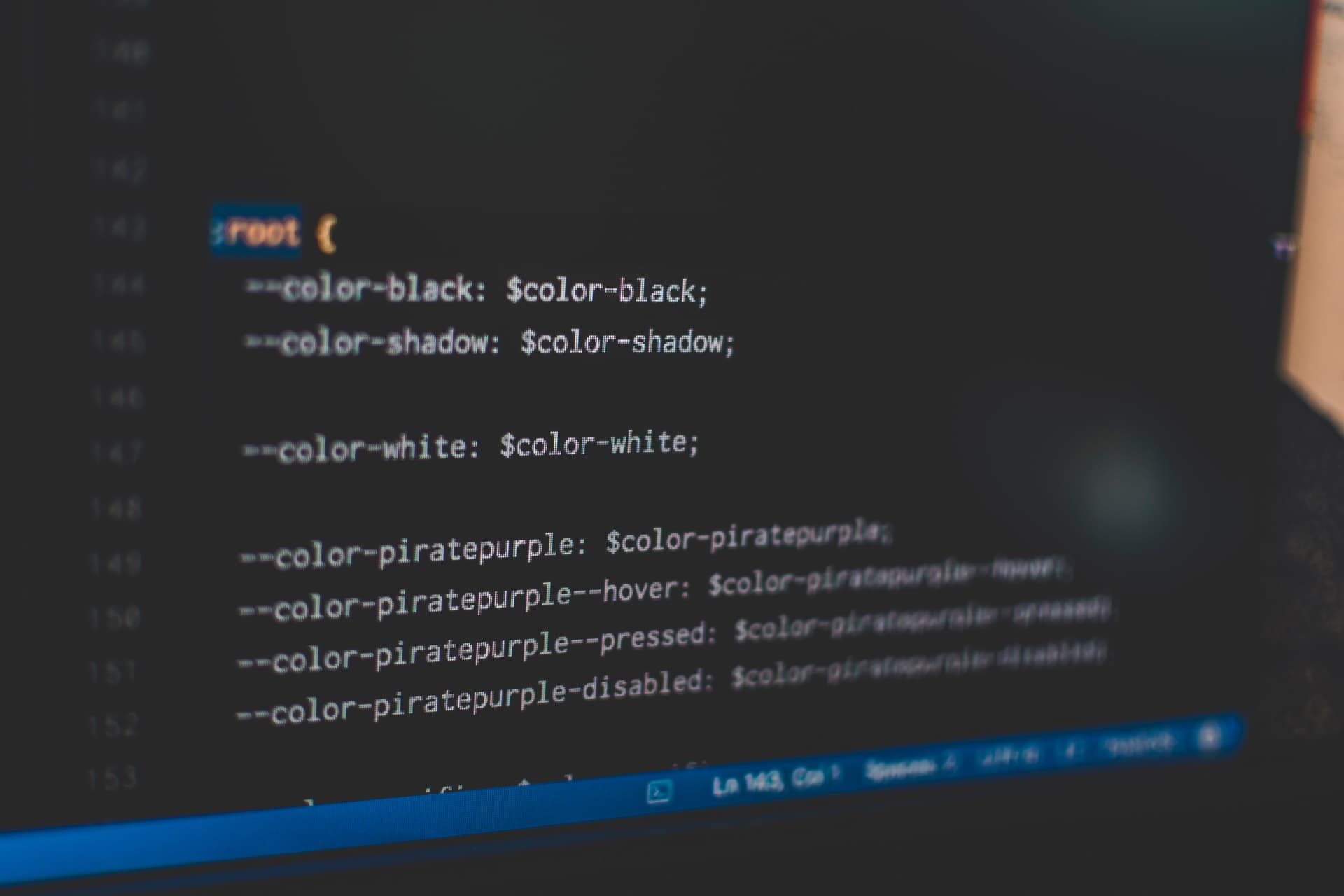
Imagine a scenario where you have a website with many pages. Most likely, you would use some colors and have some consistency. Instead of using colors ad hoc, like color: hsl(210, 96%, 40%), you could define a CSS variable and assign it a value --color-primary-500: hsl(210, 96%, 40%). The next time some “stable genius” imposes a significant rebranding on a website, changing the whole color palette, it won't be a problem—it will require a simple change of the variable value instead of changing colors in many places.
A goal of good design is to reduce the amount of code affected by each design decision so that design changes don't require code modifications in many places.
Cognitive load
The second symptom of complexity is cognitive load. It refers to information and the limitations of the human brain—how much a developer needs to know to complete a task.
Cognitive load can arrive in many ways:
- APIs with many methods
- Global variables
- Inconsistencies
- Dependencies between modules
- “Magic code” under the hood
A higher cognitive load means developers must spend more time learning the required information instead of providing value. Additionally, there is a greater risk of bugs because they can miss something important.
Of course, cognitive load is not strictly related to lines of code. Occasionally, an approach that requires more lines of code is more transparent because it reduces cognitive load. Look at this ternary operator replaced by if-statements.
// prettier-ignore
pet.canBark() ? pet.isScary() ? 'wolf' : 'dog' : pet.canMeow() ? 'cat' : 'probably a bunny'if (pet.canBark() && pet.isScary()) {
return 'wolf'
}
if (pet.canBark()) return 'dog'
if (pet.canMeow()) return 'cat'
else return 'probably a bunny'Unknown unknowns
The last of three manifestations of complexity is the worst. Unknown unknowns state that it is not obvious which pieces of code must be modified to complete a task or what information a developer must have to complete a task.
This manifestation relates to the awareness-understanding matrix. The matrix originates from a 2002 press briefing about the Iraq War. Donald Rumsfeld—the United States Secretary of Defense—divided information into four categories:
| Aware | Not aware | |
|---|---|---|
| Understand | Known knowns | Unknown knowns |
| Don't understand | Known unknowns | Unknown unknowns |
- Known knowns—facts or variables that we're aware of and understand.
- Unknown knowns—factors we know exist, but don't fully understand.
- Known unknowns—elements that we don't realize we know.
- Unknown unknowns—factors that we're not aware of and can't predict.
It's easy to imagine that being unaware of some mechanism in the system can lead to nasty bugs. That's why one of the most important goals of good design is for a system to be obvious. It is the opposite of high cognitive load and unknown unknowns.
Causes of complexity
Knowing the symptoms, we can move to the causes of complexity. The author highlights two crucial causes.
Dependencies
The first cause of complexity is dependencies. A dependency exists when one piece of code depends on another code. A given piece cannot be understood and modified in isolation.

They can be especially troubling in the JavaScript ecosystem, where we have external packages for everything. A rich ecosystem of packages is good, but before installing anything, ask yourself, “Do I need this package?” I'm not advocating reinventing the wheel, but you can write your function or script without loading a bloated library often.

A goal of software design is to decide the number of dependencies and to make them as simple and obvious as possible.
Obscurity
The second cause of complexity is obscurity. It occurs when key information is not obvious. In a big project with many dependencies, it's easy to lose track of them. Obscurity occurs when it's not obvious that a dependency exists.

Inconsistencies also play a key role in obscurity. Not sticking to conventions, using a variable name for two different purposes, and having similar functions with scrambled positions of parameters can lead to obscurities.
You probably saw some analogies in previous paragraphs. Combining symptoms with causes, we get the following conclusions.
- Dependencies lead to change amplification and a high cognitive load.
- Obscurity creates unknown unknowns and also contributes to a cognitive load.
Complexity occurs because hundreds of thousands of small dependencies and obscurities build up over time. It is difficult to eliminate the complexity after it has accumulated. Fixing a single dependency or obscurity will not, by itself, make a big difference.
Working code isn't enough
At this point, we've got a good understanding of complexity. We know its symptoms and causes. But to tackle this problem, we also need a good mindset. The author presents two approaches to programming. They sound like synonyms to me, but I won't change the terminology and will try to distinguish them properly.
- Tactical programming is the first approach. Your main focus is to get something working, such as a new feature or bug fix.
- Strategic programming is the second approach. You must invest time to improve the system's design rather than working the fastest path to finish your current project.
The second approach is a preferable way of programming. But it requires an investment mindset. You need time to polish and refine your solution. Of course, sometimes the deadlines are… well, deadly. There is no time to refactor or even write some tests. But you have to be careful using the first approach. Tactical programming is short-sighted. You borrow time from your future self and create technical debt. The complexities accumulate rapidly, especially when everyone is programming tactically. A principal thing should be the long-term design of the system. That's why you should spend 10-20% of your development time on investments. It's a suggestion—an arbitrary number. But I think it's a good number to start with.
Spend 10-20% of your total development time on investments.
Modular design
We're already aware of the issue, but how can we address it? One of the most effective strategies for managing a complex system is to divide it into smaller components and gradually introduce developers to one at a time. This approach is known as modular design.
In modular design, a software system is decomposed into a collection of modules that are relatively independent. Modules are not just classes! They are more abstract and can take many forms, such as:
- classes
- subsystems
- services
- functions
The goal of modular design is to minimize the dependencies between modules. Of course, those dependencies must cooperate, and you can't separate them. But you want to limit those dependencies.
How does the anatomy of a module look? A module consists of two parts: interface and implementation. The interface contains everything a developer needs to know to use a given module. The implementation consists of the code that carries out the promise made by the interface.

The interface describes what the modules do but not how to do it. Implementation answers the second question.
An abstraction is a simplified view of an entity that omits unimportant details. Abstractions are useful because they simplify our thinking and manipulation of complex things.
The term abstraction is closely related to modular design. We can link the definition of abstraction to modules—each module provides an abstraction in the form of its interface.
Deep modules vs. shallow modules
Now, we're getting into interesting stuff. I hope the previous sections were also interesting, but this one should be in particular (and if they were boring, maybe I'll spark your curiosity). The author states that the best modules should be deep—they should have a lot of functionality behind a simple interface.

I like this simple graphical interpretation that I redrew from the book. The oblong rectangle represents deep modules—the interface is narrow but covers a lot of functionality underneath. On the other hand, we have shallow modules. Their interface is wide without much functionality. Shallow modules are our first red flag.
A shallow module is one whose interface is complicated relative to the functionality it provides. Shallow modules don't help much in the battle against complexity because the provided benefit is negated by the cost of learning and using their interfaces.
If you prefer economic analogies, we can consider the module's costs and benefits. The module's benefit lies in its functionality, while its cost is its interface.
Classistis
There is a disease that poisons systems with many shallow modules, and it's called “classistis.” In such systems, developers are encouraged to minimize the amount of functionality in each new class. Sure, classes are individually clear, but the system as a whole is not. Our goal should be to minimize the overall complexity of a system.
Java has a similar problem. You need a complicated boilerplate code with multiple imports to open a simple file.
import static java.nio.file.StandardOpenOption.*;
import java.nio.file.*;
import java.io.*;
public class LogFileTest {
public static void main(String[] args) {
// Convert the string to a
// byte array.
String s = "Hello World! ";
byte data[] = s.getBytes();
Path p = Paths.get("./logfile.txt");
try (OutputStream out = new BufferedOutputStream(
Files.newOutputStream(p, CREATE, APPEND))) {
out.write(data, 0, data.length);
} catch (IOException x) {
System.err.println(x);
}
}
}JavaScript has its problems, but I'm glad that its creator, Brendan Eich, made it similar to Java but “not too much.”
How to deepen the modules?
We know shallow modules are problematic, so how do we deepen them? The problem comes down to the juxtaposition of generality and specialization. The over-specialization may be the most prominent cause of complexity in software. Similarly, you can complicate your life this way. Being a specialist is good (especially for your wallet), but you may have trouble communicating with others. If you would like to collaborate successfully with designers, writers, or testers, you should have some fundamentals in those fields. There is a metaphor of T-shaped skills that neatly represents this, but I'm delving into digression. Let's get back to modules.
Information hiding and leakage
The author mentions information hiding as one of the most important techniques for achieving deep modules. Information hiding means that we should reduce the amount of information needed to work with a particular module. The knowledge embedded in the module's implementation should not appear in its interface and be exposed to other modules. You can use a black box analogy here—information hiding is like treating each module as an opaque black box. You don't need to know what's going on under the hood to use it. Information hiding reduces complexity in two ways:
- It simplifies the interface of a module.
- It makes it easier to evolve the system.
Poorly designed and non-modular components often require random or extra information, exposing the inner workings. This additional information is a form of information leakage. You leak the implementation details to the module's user.
Information leakage occurs when the same knowledge is used in multiple places, such as two different classes that both understand the format of a particular type of file.
Information leakage is a crucial red flag in software design. Developing a high level of sensitivity to information leakage is one of the most valuable skills a software designer can acquire.
Defaults
Defaults illustrate the principle that interfaces should be designed to make the common case as simple as possible.
If the API for a commonly used feature forces users to learn about other rarely used features, it increases the cognitive load on users who don't need those features.
I'll show a simple example. In my codebase, I have some helpers to process MDX files (the format of my blog posts).
export async function getMDXes<Type extends MDXTypes>(
page: Extract<Pages, (typeof LINKS)['blog' | 'portfolio']>,
lang: Locale,
number: number | 'all' = 'all',
sort: 'asc' | 'desc' | 'none' = 'none'
) {
// Body of the function
}The getMDXes() function retrieves the MDX files for a specific page. I can get several files sorted by date. As you see, I use two default values. Most of the time, I want all MDXes unsorted, so it makes sense.
General-purpose modules
If the over-specialization causes complexity, we should avoid it. It should make intuitive sense—a few simple multi-purpose methods are easier to use. It reduces cognitive load. But as with many things, you should strive for balance. Implementing something that is too general-purpose may not do a good job of solving the particular problem you have today. That's why your goal should be implementing new modules in ✨somewhat✨ general-purpose fashion. The phrase means that the module's functionality should reflect your current needs, but its interface should not.
Eliminate special cases
Edge cases can hide in methods' bodies, increasing code specialization. If statements riddle such code, making it hard to understand and prone to bugs. “Okay, Matthew, but how about handling edge cases?” Designing your code where the standard case automatically handles the edge conditions should help. It may not always be possible, but we should try eliminating them wherever possible.
Together or separate
“Will they, won't they?” A good romance can't get around without this storytelling technique. It can grab us emotionally and keep us glued to a screen. Code can also keep us glued to a screen without this emotional involvement (unless it's Friday afternoon and you're tackling a nasty bug). However, like a good romance, good code should evoke a similar question—should they be together or separate? Some indicators illustrate some pieces of code are related.
- Bring together if information is shared. Separation makes it harder for developers to see the components at the same time or even be aware of their existence.
- Bring together if it will simplify the interface. When classes or methods share information, bring them together to improve readability. The code may get simpler and shorter.
- Bring together to eliminate duplication. When two or more modules are combined into a single module, it may be possible to define an interface for the new module that is simpler or easier to use than the original one.
If the same piece of code (or code that is almost the same) appears over and over again, that's a red flag that you haven't found the right abstractions.
- Separate general-purpose and special-purpose code. If you find the same pattern of code repeated over and over, see if you can recognize the code to eliminate the repetition.
This red flag occurs when a general-purpose mechanism also contains code specialized for a particular use of that mechanism. This further complicates the mechanism and creates information leakage between the mechanism and the particular case: future modifications to the use case are likely to require changes to the underlying mechanism as well.
Splitting and joining methods
The first rule of functions is that they should be small. The second rule of functions is that they should be smaller than that…
— Robert C. Martin
You probably know “Uncle Bob” and his thoughts on functions from “Clean Code.” Classic. And… I'm gonna argue with that. John Ousterhout is arguing with that, actually. He thinks length is rarely a good reason for splitting up a method. Splitting up a method introduces additional interfaces, which adds to complexity. For me, it makes sense. It's an interesting point opposite to Uncle's perspective. Shorter functions are generally easier to understand; that's true. However, our goal should be to reduce the overall system complexity. If functions are made too small, they lose their independence, resulting in conjoined methods you must read and understand together.
It should be possible to understand each method independently. If you can't understand the implementation of one method without also understanding the implementation of another, that's a red flag.
The decision to split or join modules should be based on complexity. Pick the structure that results in the best information hiding, the fewest dependencies, and the deepest interfaces. There are some ways to effectively split up methods.
Extracting a subtask
The best way to split a method is by factoring out a subtask into a separate method. The subdivision results in a child method containing the subtask and a parent method containing the remainder of the original method; the parent invokes the child. Such a division doesn't change the interface. The interface of the new parent method is the same as the original method.

I'll reuse the example from my codebase.
export async function getMDXes<Type extends MDXTypes>(
page: Extract<Pages, (typeof LINKS)['blog' | 'portfolio']>,
lang: Locale,
number: number | 'all' = 'all',
sort: 'asc' | 'desc' | 'none' = 'none'
) {
const slugs = await getMDXSlugs(page)
const mdxes = await Promise.all(
slugs.map((slug) => getCachedMDX<Type>(page, slug, lang))
)
const sorted = sort === 'none' ? mdxes : sortMDXes<Type>(mdxes, sort)
const filtered =
number === 'all' ? sorted : sorted.filter((_, index) => index < number)
return filtered
}The getMDXes() function retrieves the MDX files for a specific page. I can get several files sorted by date. At first, all logic, with sorting, was inside this one function. I extracted this task from the parent function into another. The new method is shorter, easier to read, and more manageable. The interface stays the same.
Two separate methods
The second way to break up a method is to split it into two separate methods, each visible to callers of the original method. This makes sense if the original method had an overly complex interface because it tried to do multiple things that were not closely related. If you make a split like this, the interface for each of the resulting methods should be simpler than the interface of the original method.

Multiple methods
You need to be cautious here. When you split this way, you run the risk of ending up with several shallow methods. If you're considering a split like this, you should judge it based on whether it simplifies things for callers.

Choosing names
We're getting to another big problem in software engineering—naming things. Selecting names for variables, methods, and other entities is one of the most underrated aspects of software design. Good names are a form of documentation: they make code easier to understand. You shouldn't settle for names that are just “reasonably close.” Take a bit of extra time to choose great names, which are precise, unambiguous, and intuitive. How to do it? Let's find out.
Create an image
“A picture is worth a thousand words.” There is a lot of truth to the old phrase. Unfortunately, we can't use pictures or emojis as variable names (at least in JavaScript/TypeScript). And that's a bummer because a bee is associated with buzzing, and I could use it to symbolize updates on my blog. However, when choosing a name, we could create an image in the mind of the reader. A good name conveys a lot of information about the underlying entity. “If someone sees the name in isolation, will they be able to guess what the name refers to?” Questions like this can help you paint a clear picture. You can consider names to be a form of abstraction: they provide a simplified way of thinking about a more complex underlying entity.
Names should be precise
A good name has two properties: consistency and precision. And with those two properties are associated two red flags.
If a variable or method name is broad enough to refer to many things, then it doesn't convey much information to the developer, and the underlying entity is more likely to be misused.
If it's challenging to find a simple name for a variable or method that creates a clear image of the underlying object, that's a hint that the underlying object may not have a clean design.
Use names consistently
While we're listing things, consistency has three requirements:
- Always use the common name for the given purpose.
- Never use the common name for anything besides the given purpose.
- Make sure that the purpose is narrow enough that all variables with the name have the same behavior.
Consistent naming reduces one symptom of complexity—cognitive load. Once the reader has seen the name in one context, they can reuse their knowledge and instantly make assumptions when they see it in a different context.
Avoid extra words
Every word in a name should provide useful information: words that don't help clarify the variable's meaning just add clutter. One common mistake is to add a generic noun such as “array” or “object” to a name. I was guilty of that.

Hungarian notation is a convention for variables where its name indicates the type using a prefix called “type indicator.” Early C/C++ programmers used it to help identify the variable type. However, the convention is obsolete in modern, strongly typed languages like TypeScript or Python. So, Pole and Hungarian are not two good friends, I guess.
Readers should determine readability, not the code writer—similarly to writing English. If you write code with short variable names and the people who read it find it easy to understand, that's fine.
Think twice, act once
Everything I wrote about can be summed up in this one sentence, meaning you should think more and write less—in the era of AI and coding agents, that's especially important.
You'll end up with a much better result if you consider multiple options for each major design decision.
— John Ousterhout, “A Philosophy of Software Design”